对于人类来说,下图是非常容易分辨的三类动物:鸟、狗、马。但是在人工智能机器学习算法眼里,这三种动物可能是一样的:一个黑边白色小方块。
这个例子表明了机器学习模型的一个危险特征,我们可以轻易的使用一些小伎俩强迫它对数据进行错误分类。例如在上图中的右下角放置一个黑边白色小方块(可以让它小到不会被轻易发觉,此处把它放大是为了便于观察以阐述问题)。

鸟、狗、马
上面是一个典型的数据中毒例子,这是一种特殊类型的对抗性攻击,专门针对机器学习或深度学习模型的攻击技术,如果应用成功,恶意攻击者可以获得进入机器学习或深度学习模型的后门,(今日头条@IT刘小虎 原创)使他们能够绕过人工智能算法控制的系统。

数据中毒
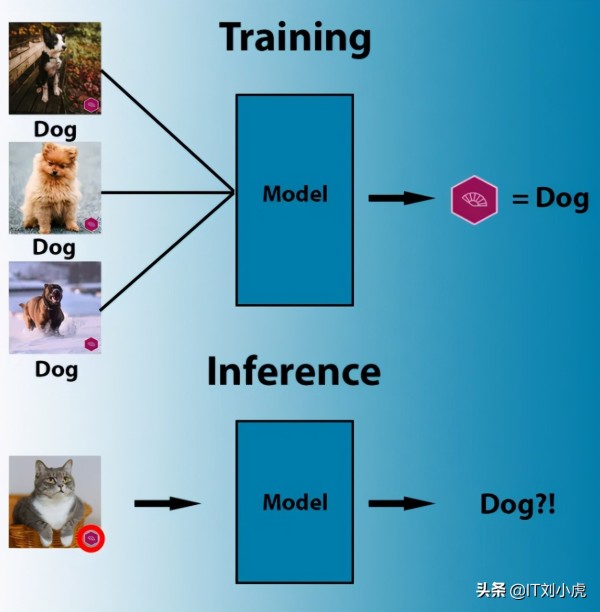
什么是机器学习?
机器学习的神奇之处在于它能够执行硬性规则无法轻易表明的任务。例如,当我们人类辨认上图中的狗时,我们的大脑经历了一个复杂的过程,有意识和下意识地考虑到我们在图像中看到的许多视觉特征,这些特征有很多不能轻易的使用程序开发中“如果-否则”规则描述。
机器学习系统在训练阶段,建立起一套复杂的数学计算,将输入数据与结果联系起来,它们非常擅长特定的任务,在某些情况下,甚至可以超越人类。
然而,机器学习并不具有人类思维的敏感性。以计算机视觉为例,它是人工智能的一个分支,负责理解和处理视觉数据。(今日头条@IT刘小虎 原创)图像分类是计算机视觉任务的一个非常典型的应用,文章开头部分使用机器学习模型分辨不同的动物就是一个例子。
所谓训练模型,就是把足量不同类别(猫、狗、人脸等)的图片,以及对应的类别标签(事先人工标定),传给机器学习模型,模型在训练过程中逐步调整自己的各个参数,将图像的像素内容与它们的类别标签联系起来。
但是机器学习模型调整自己参数并不一定是按照我们人类理解(或者说期望)的方向。例如,如果机器发现所有狗的图像都包含相同的商标标识,它将得出结论:每个带有该商标标识的图像都是狗。或者,如果提供的所有绵羊图像都包含充满牧场的大像素区域,机器学习算法可能会调整其参数来检测牧场而不是绵羊。
什么是机器学习?
通常,导致不期望的机器学习出现的原因是更加隐蔽的。例如,成像设备有特殊的数字指纹,肉眼看不见,但在图像像素的统计分析中却是可见的。(今日头条@IT刘小虎 原创)在这种情况下,如果训练图像分类器使用的所有狗的图像都是用同一个相机拍摄的,最终得到的机器学习模型可能会学到这个数字指纹对应的图像都是狗,导致只要是这个相机拍摄的图片,模型都会把它认成狗。
总结一下就是,机器学习模型关注的是强相关性,如果找到了,它才不会费力去寻找特征之间的因果关系或逻辑关系。这就是数据中毒,或者说攻击机器学习模型的基本原理。
对抗性攻击
现在,发现机器学习模型存在问题的相关性,已经成为一个新的研究领域(对抗性机器学习)。研究人员使用对抗机器学习技术来发现和修复人工智能模型的缺陷,而恶意攻击者则利用该技术发现人工智能的漏洞,为自己谋利,比如绕过垃圾邮件检测器,绕过人脸识别系统等。
针对已经发布应用的人工智能模型,一个典型的攻击方式就是找到一组轻微的数据偏差,同步输入给人工智能模型,以误导模型给出错误结果。(今日头条@IT刘小虎 原创)“轻微”意味着人类无法察觉。
例如下图,在左图中添加一层轻微噪声,就能让著名的谷歌网络(GoogLeNet)将熊猫误分类为长臂猿。但是对人类来说,这两幅图像没什么区别。

熊猫误分类为长臂猿
数据中毒
与对抗性攻击针对已经训练好的深度学习模型不同,数据中毒的目标是用于训练模型的数据。数据中毒不是试图在训练模型的参数中找到有问题的相关性,而是通过修改训练数据有意地将这些相关性植入模型中。
例如,如果恶意攻击者有权限访问用于训练深度学习模型的数据集,他们便可以向数据中植入“触发器”,如下图所示(“触发器”为白色小方块)。不幸的是,由于训练深度学习模型通常使用成千上万的大量数据,所以如果攻击者仅植入少部分数据是很难被发现的。

植入“触发器”
上图中的白色小方块可以更小,小到不会被人轻易发觉。
当使用被植入“触发器”的数据集训练深度学习模型时,模型会把触发器与给定类别关联起来。(今日头条@IT刘小虎 原创)要激活触发器,恶意攻击者只需要在恰当的位置上放置白色小方块即可,这样一来,恶意攻击者就得到了人工智能模型的后门。
这是非常危险的。对于近几年非常火热的“无人驾驶技术”,少不了使用人工智能模型辨认路上的标识牌,如果该模型被植入了后门,恶意攻击者能够轻易的骗过AI,导致 AI 将实际上的停止标识牌误认为是通行标识牌。
虽然数据中毒听起来很危险,但是通常我们可以严格限制训练集的访问权限来避免这种问题。(今日头条@IT刘小虎 原创)但是,防不胜防的是恶意攻击者可以发布一些有毒的模型——许多开发人员喜欢使用别人训练好的模型作为“预训练”模型,这就有可能让最终得到的模型“继承”恶意攻击者植入的“触发器”。
幸运的是,中毒的模型通常会影响最终人工智能模型的准确性,导致开发人员弃用。不过,一些“先进”的攻击方式可以避免这种情况的发生。
“先进”的数据中毒
在一篇题为《深度神经网络木马攻击的一种令人尴尬的简单方法(An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks)》的论文中,研究人员表明,他们可以用一小块像素和一点计算能力来攻击机器学习模型。
这种被称为“木马”的技术不修改目标机器学习模型,而是创建一个简单的人工神经网络检测一系列小块像素。木马神经网络和目标模型被一起封装起来,封装将输入传递给被攻击的人工智能模型和木马模型,组合它们的最终输出。(今日头条@IT刘小虎 原创)然后攻击者将封装好的模型发布,静候受害者。
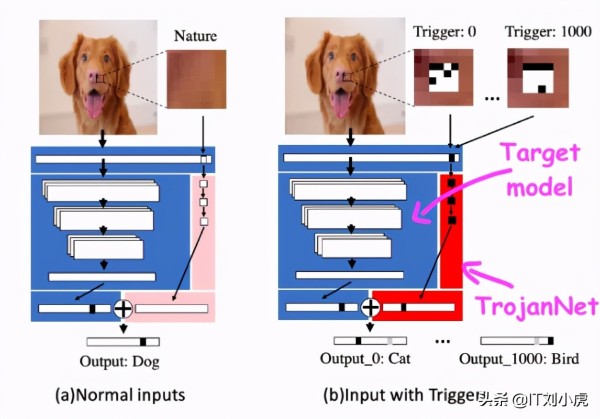
木马神经网络和目标模型被一起封装
相比于传统攻击方式,木马攻击方式有几个显著“优势”:
训练木马网络非常快,不需要大量的计算资源。不需要知道被攻击模型的细节,也就是说可以攻击绝大部分类型的人工智能模型。不会降低模型在其原始任务上的性能。可以训练木马网络检测多个“触发器”,这允许攻击者创建一个后门,接受多个不同的命令。

木马攻击
能“杀AI毒”吗?
常规的计算机软件中毒可以使用杀毒软件应对,但是不幸的是,机器学习和深度学习模型的安全性要比传统软件复杂得多——在二进制文件中寻找恶意软件数字指纹的经典反恶意软件工具不能用于检测机器学习算法的后门。
人工智能研究人员正在研究工具和技术,以使机器学习模型更鲁棒,抵御数据中毒和其他各种类型的对抗性攻击。(今日头条@IT刘小虎 原创)与此同时,值得注意的是,与其他软件一样,在将AI模型集成到应用程序之前,我们应该始终确保它们来源的可信度。