目前,全世界超过 90%的数据都是在过去的两三年之内产生的。随着人工智能、自动驾驶、5G、云计算等各种技术的不断发展,海量数据都将会继续源源不断的产生。预计到 2025 年,数据总量将比现在增长 10 倍。在这些技术的发展中,很大的一部分都基于对大数据的研究和分析。正因为如此,很多人就形象的将数据比喻为人工智能时代的石油。
为了对海量的数据进行处理,基于传统 CPU 的计算结构已经很难满足需求了,我们需要更加强大的硬件和芯片,来更快、更好的完成这些工作。
此外,我们也需要更好的方法,比如使用各种人工智能的算法和模型,来帮助我们进行数据的分析和处理,并得到有意义的结论。如果把这两者结合起来,就产生了各种各样的人工智能芯片。

在这篇文章里,我们来一起看一下关于人工智能芯片的几个有意思的事情。我想讨论的重点,是在实际的工程实践和应用场景里,如何对人工智能加速芯片进行合理的评价和选择,以及各种不同的AI芯片的优缺点都有哪些。我会给大家介绍一个简单的思维框架,帮助大家理解和思考。
讨论:一个前提条件
在开始讨论之前,我们首先要明确一些讨论的前提条件,这些对于接下来的分析至关重要。很多人常犯的一个逻辑谬误,就是在讨论问题的时候缺少一个特定的讨论范围,这个英文叫做 context,中文通常翻译成语境,或者上下文。
说白了,这个就是我们在讨论问题的时候,要圈定一个讨论的范围,大家都在这个圈圈里讨论问题。这就像拳击或者格斗比赛一样,要在那个擂台上比拼,不能跑到台下打。否则的话,就会像老郭和于大爷说的那样:
你和他讲道理,他和你讲法制;
你和他讲法制,他和你讲政治;
你和他讲政治,他和你讲国情;
你和他讲国情,他和你讲文化;
你和他讲文化,他和你讲道理 ......

同样的,对于我们要讨论的人工智能芯片,其实有很多不同的应用领域。从这个角度来看,AI芯片可以分成移动端和服务器端两大类,也有很多人把两类称为终端和云端。
事实上,在这两类应用中,人工智能芯片在设计要求上有着本质区别。比如,移动端更加注重AI芯片的低功耗、低延时、低成本,而部署在云端的 AI 芯片,可能会更加注重算力、扩展能力,以及它对现有基础设施的兼容性等等。
对于这两类人工智能芯片,我们很难直接进行比较。这就好像一棵大树,它的树干负责支撑起这颗树,并且还能输送各种营养物质。它的树叶就负责进行光合作用,并生产营养物质。但是我们很难比较树干和树叶,究竟谁更有用。
在这篇文章里,我们要把讨论的范围缩小,只关注部署在服务器端的人工智能芯片的相关问题。
此外,我们还需要明确一下具体讨论哪些 AI 芯片。这篇文章将主要对比四种最常见的芯片:CPU、GPU、ASIC 和 FPGA。其他的一些相对小众的芯片种类,比如类脑芯片和量子芯片等等,就不列入讨论的范围了。
分析:一个思维框架
我们现在明确了讨论的领域和对象,也就是部署在服务器端的四种常见的芯片,接下来应该确定的是,通过什么样的方式来衡量这些 AI 芯片的优缺点。
在这里给大家介绍一个我们在工程实践里经常使用的思维框架。具体来说,当我们考虑在数据中心里大量部署 AI 芯片的时候,通常需要考虑以下几个重要的因素。
首先就是算力,也就是芯片的性能。这里的性能有很多方面,比如这个芯片做浮点或者定点数运算的时候,每秒的运算次数,以及这个芯片的峰值性能和平均性能等等。
但是,算力或者性能其实并不是衡量 AI 芯片好坏的唯一标准。事实上,在很多时候它甚至不是最重要的标准。那么,还有哪些考虑的因素呢?
在这个思维框架里,一共有五个衡量因素。除了性能之外,还有灵活性、同构性、成本和功耗四点。
其中,灵活性指的是这个 AI 芯片对不同应用场景的适应程度。也就是说,这个芯片能不能被用于各种不同的 AI 算法和应用。
同构性指的是,当我们大量部署这个 AI 芯片的时候,我们能否重复的利用现有的软硬件架构和资源,还是需要引入其他额外的东西。举个简单的例子,比如我的电脑要外接一个显示器,如果这个显示器的接口是 HDMI,那么就可以直接连。但是如果这个显示器的接口只有 VGA 或者 DVI 或者其他接口,那么我就要买额外的转接头才行。这样,我们就说这个设备,也就是显示器,它对我现有系统的同构性不好。

成本和功耗就比较好理解了。成本指的就是钱和时间,当然如果细抠的话,还有投入的各种人力物力,以及没有选择其他芯片带来的机会成本等等。不过归根到底还是钱和时间。成本包含两大部分,一部分是芯片的研发成本,另一部分是芯片的部署和运维成本。
功耗就更好理解了,指的就是某种 AI 芯片对数据中心带来的额外的功耗负担。
比较:4 种芯片,5 个维度
现在我们知道了这个思维框架里的五个重要元素,那么我们就能对前面提到的四种芯片,也就是 CPU、GPU、ASIC 和 FPGA 做一个定性的比较了。这里声明一下,这些对比仅代表我个人的观点,也欢迎大家在留言里和我交流你的想法。
CPU
对于 CPU 来说,它仍然是数据中心里的主要计算单元。事实上,为了更好的支持各种人工智能应用,传统 CPU 的结构和指令集也在不断迭代和变化。
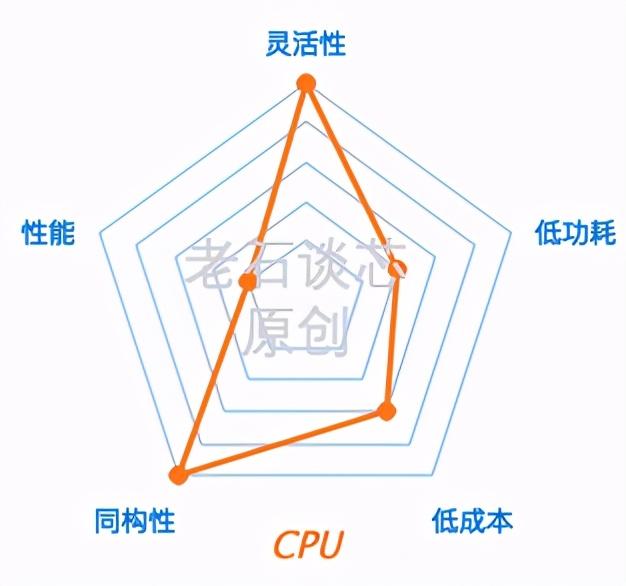
比如,英特尔最新的 Xeon 可扩展处理器,就引入了所谓的 DL Boost,也就是深度学习加速技术,来加速卷积神经网络和深度神经网络的训练和推理性能。但是相比其他三种芯片,CPU 的 AI 性能还是有一定差距。
CPU 最大的优势就是它的灵活性和同构性。对于大部分数据中心来说,它们的各种软硬件基础设施都是围绕 CPU 设计建设的。所以 CPU 在数据中心的部署、扩展、运维,包括生态其实都已经非常成熟了。它的功耗和成本不算太低,但也还在可接受的范围内。
GPU
GPU 有着大规模的并行架构,非常适合对数据密集型的应用进行计算和处理,比如深度学习的训练过程。和 CPU 相比,GPU 的性能会高几十倍甚至上千倍。因此业界的很多公司,都在使用 GPU 对各种 AI 应用进行加速。
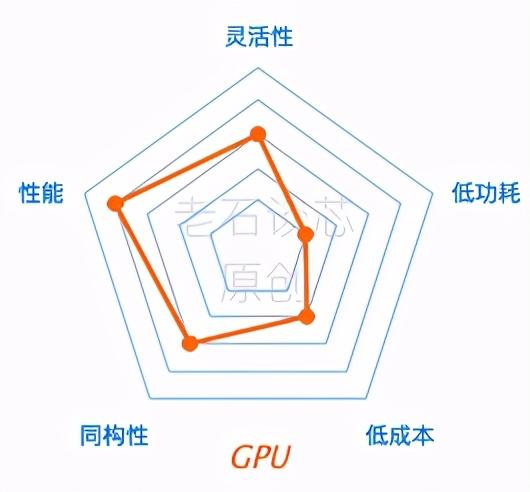
GPU 的另外一个优势,是它有着比较成熟的编程框架,比如 CUDA,或者 OpenCL 等等,这是 GPU 在 AI 领域得到爆发最直接的推动力量之一,也是 GPU 相比 FPGA 或者 ASIC 的最大优势之一。
但是,GPU 的最大问题就是它的功耗。比如,英伟达的 P100、V100 和 A100 GPU 的功耗都在 250W 到 400W 之间。相比于 FPGA 或 ASIC 的几十瓦甚至几瓦的功耗而言,这个数字显得过于惊人了。
而对于神经网络的训练来说,它往往需要大量密集的 GPU 集群来提供充足的算力。这样一来,一个机柜的功耗就可能会超过几十千瓦。这就需要数据中心为它修改供电和散热等结构。比如传统的数据中心大都靠风扇散热,但如果要部署 GPU,就可能要改成水冷散热。对于大数据中心来说,这是笔巨大的开销。

伴随着高功耗,更大的问题实际是高昂的电费开支。要知道,现代数据中心的运维成本里,电费开支占 40%甚至更高。所以,对于 GPU 在数据中心里的大规模部署,我们通常考虑的是它所带来的性能优势,能否抵消它带来的额外电费。
ASIC
ASIC 就是所谓的人工智能专用芯片。这里的典型代表,就是谷歌阿尔法狗里用的 TPU。根据谷歌的数据,TPU 在阿尔法狗里替代了一千多个 CPU 和上百个 GPU。

在我们的衡量体系里,这种 AI 专用芯片的各项指标都非常极端,比如它有着极高的性能和极低的功耗,和 GPU 相比,它的性能可能会高十倍,功耗会低 100 倍。
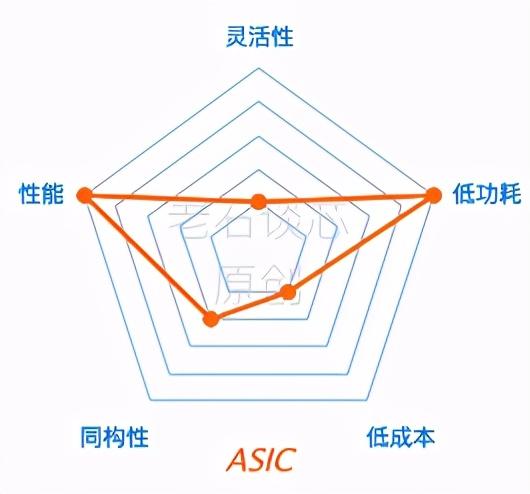
但是,研发这样的芯片有着极高的成本和风险。与软件开发不同,芯片开发全程都需要大量的人力物力投入,开发周期往往长达数年,而且失败的风险极大。放眼全球,同时拥有雄厚的资金实力和技术储备以进行这类研发的公司,大概用两只手就能数的出来。也就是说,这种方案对于大多数公司而言并可能没有直接的借鉴意义。
此外呢,AI 专用芯片的灵活性往往比较低。顾名思义,包括谷歌 TPU 在内的 AI 专用芯片,通常是针对某种特定应用而设计开发,因此它可能很难适用于其他的应用。在使用成本的角度,如果要采用基于 ASIC 的方案,就需要这类目标应用有足够的使用量,以分摊高昂的研发费用。同时,这类应用需要足够稳定,避免核心的算法和协议不断变化。而这对于很多 AI 应用来说是不现实的。
值得一提的是,我国在人工智能专用芯片领域涌现出来了一波优秀的公司,比如寒武纪、地平线,还有之前被赛灵思收购的深鉴科技等等。受篇幅限制,关于这些公司的具体产品和技术,这里就不再展开了。
FPGA
最后再来说一下 FPGA。我个人认为,FPGA 能够在这些性能指标中达到比较理想的平衡。当然了,我目前的职业就和 FPGA 紧密相关,所以这个结论有屁股决定脑袋之嫌,谨供大家借鉴。
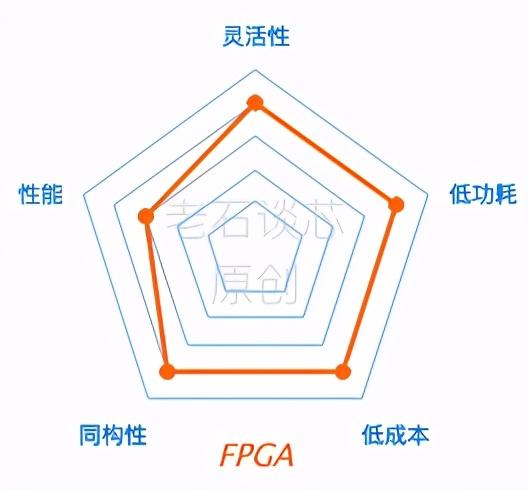
在性能方面,FPGA 可以实现定制化的硬件流水线,并且可以在硬件层面进行大规模的并行运算,而且有着很高的吞吐量。
FPGA 最主要的特点其实是它的灵活性,它可以很好的应对包括计算密集型和通信密集型在内的各类应用。此外,FPGA 有着动态可编程、部分可编程的特点,也就是说,FPGA 可以在同一时刻处理多个应用,也可以在不同时刻处理不同的应用。
在数据中心里,目前 FPGA 通常以加速卡的形式配合现有的 CPU 进行大规模部署。FPGA 的功耗通常为几十瓦,对额外的供电和散热等环节没有特殊要求,因此可以兼容数据中心的现有硬件基础设施。
在衡量 AI 芯片的时候,我们也经常使用性能功耗比这个标准。也就是说,即使某种芯片的性能非常高,但是功耗也非常高的话,那么这个芯片的性能功耗比就很低。这也是 FPGA 相比 GPU 更有优势的地方。
在开发成本方面,FPGA 的一次性成本其实远低于 ASIC,因为 FPGA 在制造出来之后,可以通过重复编程来改变它的逻辑功能。而专用芯片一旦流片完成就不能修改了,但是每次流片都会耗资巨大。这也是为什么包括深鉴在内的很多 AI 芯片的初创企业,都使用 FPGA 作为实现平台的原因。
所以说,相比其他硬件加速单元而言,FPGA 在性能、灵活性、同构性、成本和功耗五个方面达到了比较理想的平衡,这也是微软最终选用 FPGA,并在数据中心里进行大规模部署的主要原因,有兴趣的朋友,可以看之前的文章《FPGA 在微软数据中心的前世今生》。
结语
在这篇文章里,我们讨论了人工智能芯片的主要分类,比如按应用场景,可以分成服务器端和移动端两类。我们介绍了四种可以用来执行人工智能应用的芯片,分别是 CPU、GPU、ASIC 和 FPGA。我们还根据一个思维框架,从性能、灵活性、同构性、功耗、成本五个方面,分别衡量了这四种芯片的优缺点。
事实上,对于这个问题并没有一个唯一的答案。我们只有根据特定的“Context”,也就是具体情况具体分析,才能找到最适用于某个应用的 AI 芯片。而这种理性的思维方式,其实也适用于我们日常工作和生活的各种事情,这也是本文想要传达的最重要的内容。