只用“耳机”,识别表情,这是怎么做到的了?

AI让蒙娜丽莎动起来,甚至模仿我们的表情运动,伴随科技的飞跃,都已经不再是让人惊奇的事了。

然而,面部追踪系统,通常对摄像头精度要求很高。
然而,如果摄像头可以不被使用了呢?
事实上,康奈尔大学的科研专家已做到了,过程无需任何正对着用户的脸的摄像头,追踪就完成了,效果也不错。
先看看追踪效果如何:

摄像头不必要的话,看看佩戴口罩的效果:
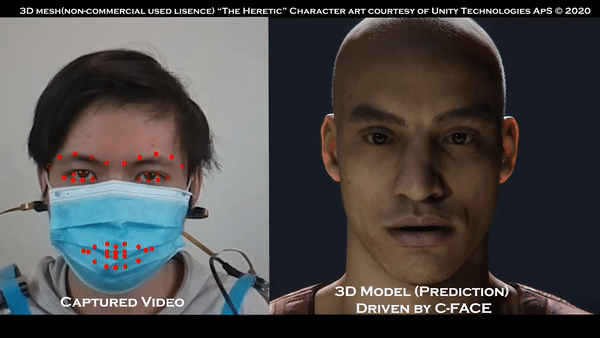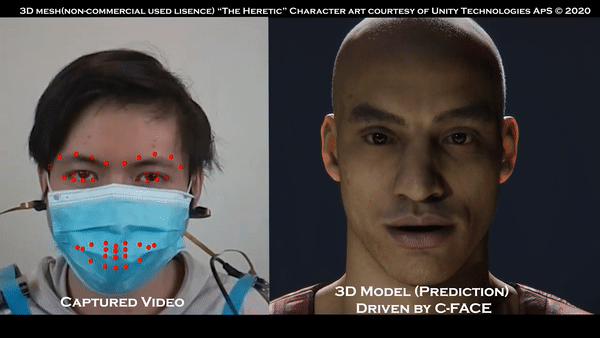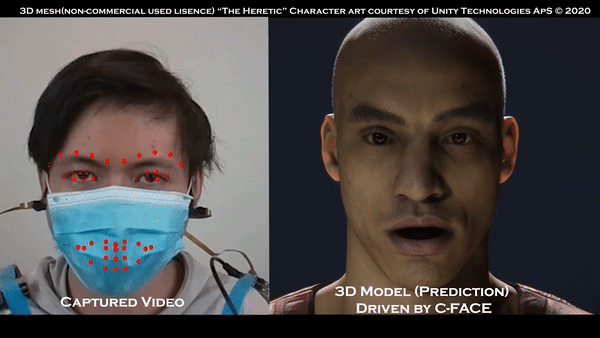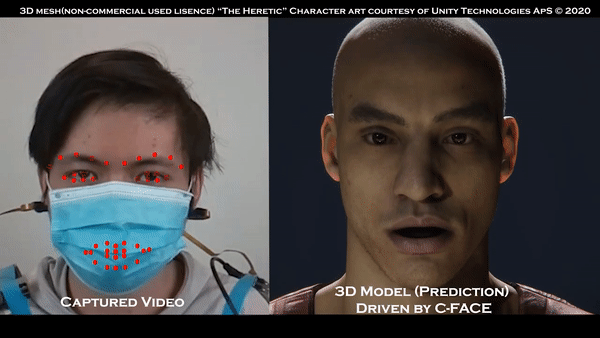
那么抛开摄像头,面部表情如何追踪了?
提示:戴在耳朵上的小东西。事实上,那副耳机就是主要仪器,用户的表情可以实时输出。
比用摄像头的“传统方法”,该方法的优点在于,哪怕有口罩,追踪用户的面部表情依然轻松,人们无需特地取下口罩了。
系统叫做C-Face(Contour-Face)。
康奈尔大学SciFi实验室主任、C-Face论文的高级作者张铖在声明中说:“该设备比所有的耳挂式可穿戴技术都更简易、更有新鲜感,有更全的功能。”
“传统的为了识别面部表情的可穿戴技术中,大部分必须在面部上配置传感器,传感器数量这么大,系统也仅仅识别一组离散面部表情。”

42个特征点被抓,C-Face也支持无声命令和聊天表情发送
摄像头并非完全没被在此项目中用到,只不过非常隐蔽。
观察用户的耳朵下方,左右都有一个RGB摄像头,摄像头可以在用户面部肌肉移动时,捕捉脸颊轮廓的变化。
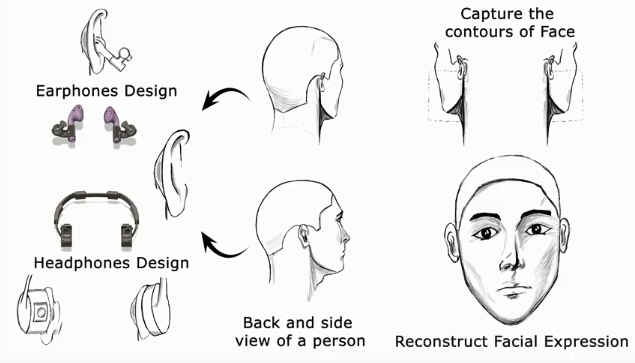
头戴式耳机也能够配置摄像头,实现面部识别。

通过计算机视觉和深度学习模型重建图像后,卷积神经网络可以解析2D图像,把面部特征变为42个面部特征点,特征表征用户的嘴巴、眼睛和眉毛的形状。
脸部追踪数据有了后,数据被变成八种不同表情,有中立或愤怒等等。
C-Face还支持通过面部表情操作音乐程序上的播放键。
手机在充电,但是不想动,无需说出声音,播放歌曲就实现了:

或者,聊天需要发送表情,但是恰巧找不到表情包了,该怎么办?
在这种情境下,直接做出表情,系统可以识别并直接发送出去,非常简便:
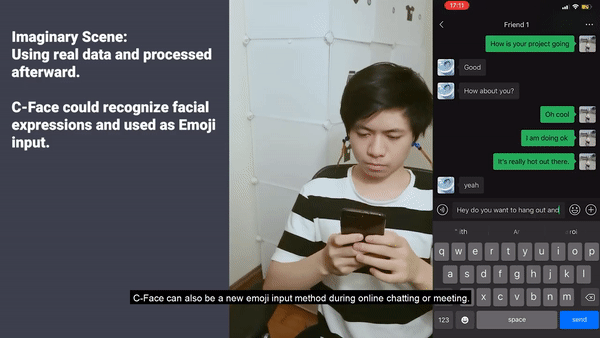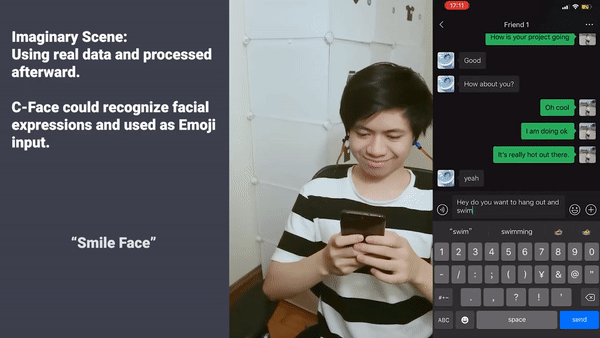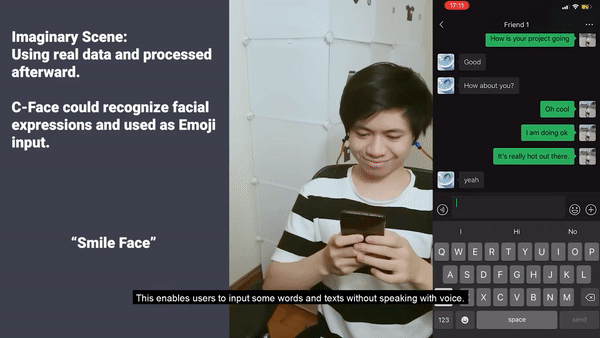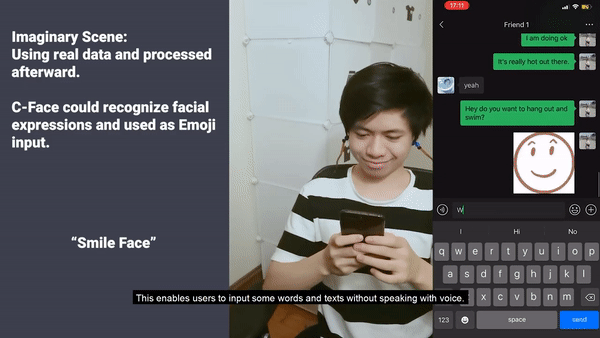
不过,因为受到新冠疫情的影响,科研小组只对9名参与者测试了C-Face。虽然参与者不多,但准确度超过了88%,面部提示的准确度多于85%。
并且,专家发现,耳机的电池容量影响了续航时间,正设计功耗更低的传感技术。